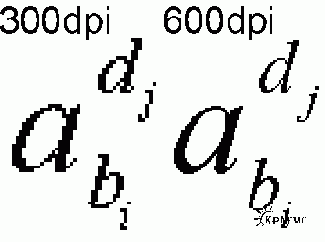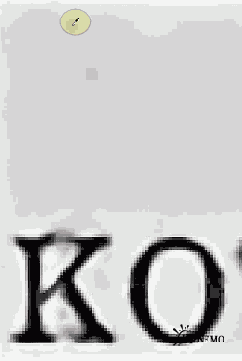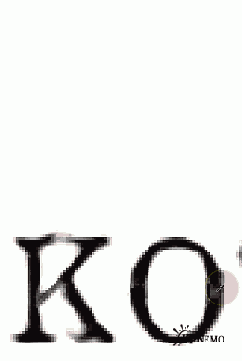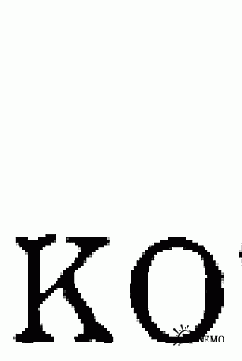Подборка статей с сайта Kpnemo.ru. Большая благодарность Ивану Сторожеву (IvanStorogev) - создателю статей, за подробные алгоритмы работы с материалом, за проделанную работу.
Обработка, компиляция в chm - Kendzin.
Как почистить сканы книг. Часть 1.
Как почистить сканы книг. Часть 2.
Как почистить сканы книг. Часть 3.
Как почистить сканы книг? Часть 1.
В статье описана очистка сканов книг непосредственно после сканирования, перед дальнейшей обработкой. Речь будет идти только о черно-белых книгах (текст и штриховые рисунки). Обработку книг с цветными картинками нужно разбирать отдельно.
А зачем?
После сканирования книги её предполагается выкладывать в сеть (или хранить у себя на диске).
Здесь есть 2 пути:
1) Можно распознать сканы в программе OCR, например FineReader (FR).
Если качество оригинала хорошее, например распечатка на лазернике с размером шрифта 12pt, то FR прекрасно распознает её без всяких дополнительных мер. Но вот если распознавать нужно старую книжку, на желтой неровной бумаге, грязную и т. п… Тут предварительная очистка резко повысит качество распознавания, а это значит, что гораздо меньше труда и времени уйдет на вычитку, т.е. ручное исправление ошибок. Надо сказать, что встроенные в FR средства очистки картинки довольно примитивные, так что с плохими, зашумленными сканами он справляется неважно.
2) Можно хранить нераспознанной, в виде растровой картинки, в том или ином формате: DJVU, PDF, TIFF.
Здесь предварительная очистка ещё уместнее. Во-первых, очищенный скан гораздо приятнее и не так утомительно читать. Во-вторых, что ещё важнее, после очистки сканы гораздо, в десятки раз, лучше сжимаются в любой формат. Дело в том, что случайные точки на изображении (шум) практически не сжимаемы, особенно когда их много.
Для очистки изображений применяется много различных методов и программ, порой стоимостью в тысячи и десятки тысяч долларов. Я опишу простой и доступный способ, особенно ценный тем, что руками придется работать только с одной страницей книги, остальные можно обработать автоматически, основываясь на сохраненных параметрах.
1-й этап: сканирование
Сканировать книжку нужно обязательно в режиме grayscale (серый). Обратите внимание: сканировать в режиме b/w (черно-белый) нельзя! В режиме b/w дальнейшая обработка будет невозможна.
Можно сканировать в true image (полноцвет), но это сильно замедлит обработку, увеличит объем файлов, а особенного выигрыша не даст. Исключение составляют случаи, когда на страницах есть цветные пятна грязи, тут работа с цветом может сильно помочь.
Некоторые сканеры позволяют выбрать один из цветовых каналов (красный, зеленый, синий), который будет использоваться при сканировании в серый, есть и другие настройки и их также можно покрутить. Но не увлекайтесь, большая часть фич сканера просто обработка картинки драйвером. То же самое можно сделать в фотошопе, только куда лучше.
Попробуйте разные варианты, выбирать нужно тот, где изображение контрастнее, буквы выглядят более четкими. Если при этом мелких шумов (например, фактура бумаги) будет, в разумных пределах, больше -- это неважно, уберем потом.
Наоборот, если на бумаге есть крупные, размером в 2-3 буквы и больше, пятна, то нужно постараться подобрать настройки сканера так, чтобы эти пятна были бледными, по сравнению с буквами, пусть и ценой менее контрастных, по сравнению с другими вариантами букв.
Проще говоря, настраивайте сканер так:
1) Если крупных пятен нет, то главное сделать четкими буквы, а на шум особенно не глядеть.
2) Если крупные пятна есть, то главное их прибить, даже если буквы будут не такие уж четкие.
В том и другом случае нужно не перебарщивать, руководствуясь опытом и здравым смыслом.
Если вы пользуетесь для сканирования FR, то уберите в опциях сканирования «Очистить изображение», «Устранить искажение строк», «Делить развороты». Всё это вы сделаете потом, когда почистите сканы и втяните их обратно в FR. На этом этапе любая обработка изображения в FR только замедлит сканирование и ухудшит чистку изображения в более подходящих программах.
О выборе разрешения скана. Обычно книжки с текстом сканируют с разрешением 300dpi. Это подходящее значение для чистого текста, приличного качества полиграфии и не слишком мелкого шрифта, короче очередной бестселлер типа: "Глухой против Слепого". Но в этом случае и чистка изображения не требуется. При зашумленном изображении, мелком шрифте нужно сканировать с разрешением 600dpi. Это сильно облегчит очистку и качество окончательного файла, если вы не будете распознавать книгу, а сохраните в виде сжатого растра. Не беспокойтесь о величине окончательного файла. Хорошо почищенная книга с разрешением 600dpi при сжатии в DJVU дает файл немногим больших размеров, чем с разрешением 300dpi.
Растровая форма хранения книг особенно часто применяется для книг с формулами. В этом случае сканирование с разрешением 600dpi обязательно, иначе трудно будет разобрать индексы в формулах, отличить похожие буквы, например "омега" и w. А ведь в математике нередки вложенные индексы (индекс индекса). Там при сканировании с разрешением 300dpi вообще трудно что-либо разобрать, тем более распечатать. Вот смотрите:
Буквы i и j на картинке слева трудно отличить друг от друга. А ведь это не скан, а печать в файл. При сканировании всё будет гораздо хуже -- маленькая точка на бумаге и всё, и 2 балла на экзамене
!
Таким образом:
Сканировать для наших целей нужно с разрешением 600dpi!
В крайнем случае, 400dpi.
Теперь нужно выбрать образцовую страницу для настройки программ обработки, чтобы остальные обработать автоматически, в пакетном режиме. Выберите самую обычную, типовую страницу, может быть слегка более грязную, чем в среднем.
Посмотрите все отсканенные страницы книги, может быть некоторые нужно пересканить.
Все сильно загрязненные, искаженные, с более мелким шрифтом, чем остальные, с очень крупными пятнами, с рисунками на всю или почти всю страницу и т.п. сразу положите в отдельную папку. Их проще обработать отдельно, по одной. Обычно таких немного.
Дальше приступим к обработке сканов последовательно в программе NeatImagePro+, потом в PhotoShop’е. Начнем с первой.
2-этап: NeatImagePro
Нам понадобится программа NeatImagePro+ (NI+) , у неё множество уникальных возможностей, например с её помощью можно делать замечательные "гламурные" картинки обнаженной натуры. Вот её сайт: www.neatimage.com. Но нам туда не надо, там её свободно не раздают. К счастью, у Вас есть я, а у нас всех Рапидшара:
Neat Image Pro+ Edition v5.0.5.0
пароль:))))))
Это не самая последняя версия, зато с лекарством и вполне рабочая.
NI+ работает следующим образом: выделяется характерный участок картинки с шумом, но без полезного изображения. Программа этот участок оценивает и "вычитает" шум из всей картинки.
Я закавычил "вычитает" потому, что на самом деле не "вычитает", а умножает, и не картинку на шум, а их двухмерные спектральные представления. Да и не умножает, если в школьном смысле… Но мы в эти дебри не полезем :-).
Главное окно программы организовано в виде вкладок:
1) Вкладка: Input Image
Про то, как загрузить файл в программу, я рассказывать не буду, замечу лишь, что NI+ не желает открывать 8-битный TIFF, если он сохранен, например из PhotoShop’а как индексированный 8-битный с палитрой, но нормально открывает, если TIFF сохранить как grayscale.
2) Вкладка: Device Noise Profile
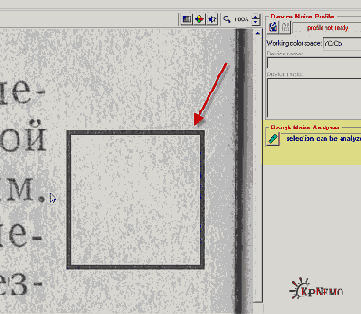
На этом этапе мы должны выбрать участок скана, где нет букв и рисунков, но есть характерные шумы. Обратите внимание: темные полосы около корешка или на краях тоже не должны попасть в наш выбор. На выделенный участок показывает стрелка на Рис. 1:
Рис. 1 (щелкнуть, чтобы увеличить)
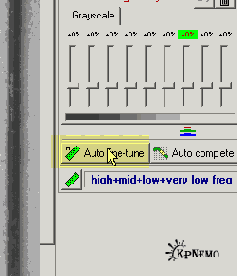
После того, как мы выделим подходящий участок, надо щелкнуть по кнопке "Rough Noise Analyzer" на левой панели, на Рис.1 подсвечена желтым. Некоторое время наблюдаем за синей полоской… и на левой панели, под упомянутой кнопкой, появятся дополнительные настройки (Рис. 2).
Рис. 2
Проще всего нажать на кнопочку "Auto fine-tune" (подсвечена желтым), и перейти к вкладке:
3) Вкладка: Noise Filter Settings
Здесь мы настроим фильтр так, чтобы сделать максимально четкими буквы и убить шумы. Перед настройкой фильтра нужно выделить участок подходящий участок с полезным изображением и увеличить его на весь экран. При выборе участка нужно руководствоваться следующими соображениями:
1) Брать нужно, по возможности, максимально зашумленный участок
2) Одновременно этот участок должен с наиболее мелким деталями полезного изображения, например с мелким шрифтом.
Поскольку мы обрабатываем не фотографию любимой кошки, а текст, то естественность изображения нас не волнует. Главное, чтобы буквы были почетче, а шума поменьше. Поэтому смело двигаем движки на левой половине панели и смотрим, что получается. Обращайте внимание на мелкие детали букв: хвостики, например сравнивайте "C" и "G"; внутренние участки букв, например в верхней части строчной "е".
Описывать действие каждого движка я не буду, проще пробовать и смотреть.
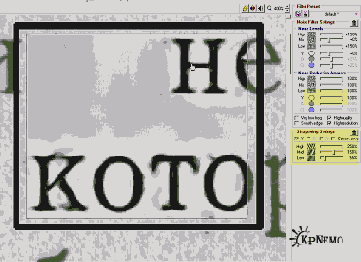
Рис. 3 (щелкнуть, чтобы увеличить)
На картинке (Рис. 3) изображен результат обработки, а положение движков и чекбоксов можно взять за точку отсчета при собственных экспериментах. В основном играйте движками в "Noise reduction Amounts", особенно движок "Y"; "Sharpening Settings". Эти участки левой панели на рисунке подсвечены желтым. Когда результат вам понравится, подвигайте прямоугольник Preview по всему изображению, чтоб прикинуть, как оно будет выглядеть в разных местах. Если все хорошо, сохраните полученный профиль фильтрации, он будет использован для пакетной обработки остальных страниц.
4) Вкладка: Output Image
Здесь вы можете нажать на Apply и посмотреть, что получилось. А если вы уверены, что настроили NI+ хорошо, то сразу переходите к пакетной обработке остальных страниц. Просто нажмите Esc, и вы попадете в окно пакетного обработчика.
5) Окно пакетного обработчика
File -> Bath, добавляете нужные страницы (не забудьте в "Filter Presets" пометить "Use specified preset" и выбрать сохраненный прежде, при настройке по образцовой странице пресет. Наконец можно запустить процесс обработки. Он долгий, поэтому запустите его на ночь, или, наоборот, с утра, перед уходом на работу.
Дальше нужно продолжить чистку в Фотошопе, но об этом в следующей части, которая будет опубликована, если эта вызовет интерес и желание продолжения у юзеров kpnemo.
Подборка статей с сайта Kpnemo.ru. Большая благодарность Ивану Сторожеву (IvanStorogev) - создателю статей, за подробные алгоритмы работы с материалом, за проделанную работу.
Обработка, компиляция в chm - Kendzin.
Как почистить сканы книг. Часть 1.
Как почистить сканы книг. Часть 2.
Как почистить сканы книг. Часть 3.
Как почистить сканы книг? Часть 2.
В первой части статьи мы остановились на этом:
Пойдём дальше. Вторая часть статьи.
Использование Photoshop’а (Curves) для чистки сканов книг + философское отступление.
Напомню, речь идет только о черно-белых книгах (текст и штриховые рисунки). Не о цветных.
* * *
В отзывах к первой части статьи прозвучал много хороших слов и благодарностей. Большое спасибо всем, кто нашел время откликнутся, написать пару строк в комменты, тем более с добрыми словами в мой адрес. Доброе слово, как говорится, и кошке приятно. Всем удачи :-)
Надеюсь, однако, что будет больше замечаний непосредственно по теме. Делитесь своими наработками, рецептами. Некоторые блогеры упомянули о других программах/способах обработки сканов – напишите о них, это будет интересно всем. Профессионалы, расскажите о более серьезных программах, а можно и выложить...
Критикуйте, дополняйте эту статью (это касается всех частей)-- ведь это выгодно всем.
* * *
Философское отступление
Да, я знаю, что надо не грузить общими рассуждениями, а говорить конкретно. Но любое дело лучше делать осмысленно. Осмысление же требует хотя бы самого общего представления о сути предмета. Поэтому, пожалуйста, прочтите последующие несколько абзацев не спеша, вдумчиво. Может быть они будут Вам полезны не только в деле очистки сканов книг. Возможно, Вам покажутся общеизвестными высказанные там мысли, но, как показывает опыт общения, это не так.
Если влом читать неконкретные вещи, то можно сразу перейти к Photoshop: Curves, всё, что там написано, можно понять и не читая раздел Философское отступление
Итак, пару слов о шуме (помехе), (полезном) сигнале и фильтрации, в самом общем плане, безотносительно к обработке изображения.
Сигнал.
Имеется ввиду полезный сигнал. Сигнал – это то, что нам нужно..
Это исчерпывающее определение. Например, сигналом может быть часть картинки -- изображение текста в примере, который мы разбираем. Или голос исполнителя в музыкальном клипе. Или правда в речах политика, если она там есть. И всё, что угодно.
Шум.
А шум, помеха, это то, что нам не нужно. Например фон текста на картинке (фактура бумаги, пятна, следы грязи на стекле сканера). Или звучание музыкальных инструментов в муз. клипе, если мы хотим выделить голос исполнителя. Или вся речь политика, если правды там нет.
Фильтрация, это процесс разделения сигнала и шума. Это может быть некое электронное или механическое устройство, компьтерная программа. Разум слушателя, если речь идет о словах политика...
Для того, чтобы фильтрация была осуществима, сигнал и шум хоть в чем-то, но должны отличаться. Т.е. мы должны найти параметры, свойства, по которым отличаются шум/сигнал и увеличить это различие.
Вернемся к сканам книги. На краях и переплета после сканирования часто бывают черные полосы. Это тоже шум. От полезного сигнала, изображения текста, он отличается расположением в двумерном пространстве изображения страницы, поэтому отделить его легко руками и относительно легко автоматически. Стоит, однако, неплотно прижать толстую книгу при сканировании и черная полоса будет пересекаться с текстом. И всё, выделить текст в этом месте методами обработки изображения станет невозможно. Но если речь идет всего о 1-2 буквах в начале (конце) строки, мозг, почти на 100% восстановит недостающие буквы. Вдь ткст очн избтчн, при удални глснх всё ещ мжно пнть о чм рчь. Однако фильтрация и восстановление будет идти не изображения, а текста как последовательности букв и слов, с учетом их смысла, семантики.
Программа NeatImage, описанная в 1-ой части статьи использует другой критерий различения шума и сигнала – разницу в двумерных спектрах сигнала и шума. Обратите внимание: указывать где шум, а где сигнал нам пришлось самостоятельно. В иных случаях шум и сигнал могут поменяются местами. Например, криминалисту может быть задан вопрос: — "Где взята бумага, на которой написана жуткая записка?". И фактура бумаги была бы полезным сигналом, а изображение текста – шумом. В 3-й части статьи будет описана работа с фильтром Фотошопа Smart Blur. Там используются другие критерии разделения сигнала и шума.
Вывод
Нужно обязательно понимать, по какому критерию происходит разделение сигнала и шума в используемых вами процедурах фильтрации. Тогда можно будет выработать более эффективный метод обработки.
Ведь если мы по очереди применим несколько фильтров с разными критериями фильтрации, то результат будет хороший. Если же фильтры обрабатывают по одному и тому же критерию, то с какого-то момента, улучшения не будет, а то и начнется ухудшение разделения.
* * *
Photoshop: Curves
Здесь описана работа с Фотошопом, но подобный инструмент есть в любом достаточно мощном растровом редакторе: Gimp, Corel Photopaint, PaintShop Pro и др. Алгоритмы у всех одинаковы. Важно лишь наличие у редактора режима пакетной обработки.
Итак, инструмент Curves. Что, собственно, мы им сделаем? Это очень просто: разделим шум и полезное изображение по критерию яркости. Всё, что будет белее некоторого порога, станет максимально белым. Соответственно всё, что будет темнее некоторого порога, будет совершенно черным. Все наши усилия будут направленны как раз на установление этих порогов так, чтобы фон попал в белое, а текст – в черное. Имейте ввиду, если после предыдущих этапов обработки на изображении есть участки шума более темные, чем наиболее светлые участки текста, то Curves их не только не удалит, а наоборот – подчеркнет.
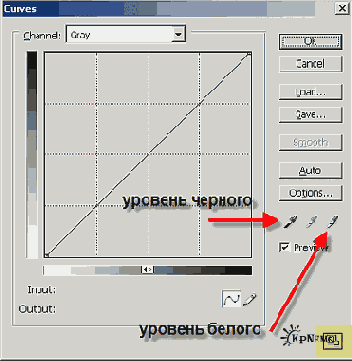
Вызываем Curves (Меню: Image --> Adjustments --> Curves или просто Ctrl-M). На Рис. 1 стрелками указаны две пипетки: "Уровень черного" и "Уровень белого". Орудуя ими по очереди мы и подгоним пороги так, чтобы текст было побольше, а шума поменьше. Серая пипетка нам не нужна. Кнопка в правом нижнем углу (подсвечена желтым) увеличивает окошко или делает его компактным.
Рис. 1
Перед вызовом Curves нужно увеличить изображение на весь экран так, чтобы были целиком видны 3-4 буквы. Обязательно должна попасть точка и запятая, буквы с мелкими деталями. Лучше выберите сильно зашумленный участок, там где шум более темный. По возможности выберите участок с мелким шрифтом, например текст сноски внизу страницы.
Теперь по очереди, чередую пипетки, щелкайте на белой -- на участках с шумом, черной -- на полезных участках картинки, на буквах.
Когда будет работать пипетками, контролируйте следующие критерии, они выбраны с учетом характерных ошибок FineReader'а:
-- точка "." и запятая "," должны отличаться
-- белый участок внутри букв "е", "о", "R" и т.п не должен быть залит черным
-- мелкие детали букв должны быть различимы, например хвостик у курсивной "а", она не должна превращатся в "о",
-- следите за "коромыслом" у буквы "й", точкой над "i" и другими подобными элементами букв
-- обратите внимание на верхние (и нижние) индексы, например значки и цифры, указывающие на сноску
-- мелкие разрывы в вертикальных участках широких букв – "м", "ш" -- не страшны
-- в горизонтальных/наклонных участках букв "н", "и", "п" разрывов быть не должно. FR немедленно начинает их путать
На рисунках 2-6 показаны скриншоты последовательной настройки уровней белого и черного. Пипетка выделена овалом. Розовым – черная, желтым – белая.
Рис. 2
Рис. 3
Рис. 4
Рис. 5
Рис. 6
Когда настроите Curves, сохраните профиль: "Save...". Он будет использован потом, при пакетной обработке остальных страниц.
Вот что получилось:
Рис. 7
В начале первой части статьи я говорил о том, как влияет очистка изображения на степень сжатия. Посмотрите как последовательно уменьшаются размеры картинок от 2-й до 7-й. С 8806 байт до 1376. Это хорошая иллюстрация к упомянутому утверждению.
Теперь надо записать Action, чтобы автоматически обработать Фотошопом остальные страницы. В нем будет всего две команды:
1) Curves, c ранее сохраненным профилем
2) Image --> Mode --> Bitmap...
Выскочит окошко Bitmap
В строке "Resolution" оставьте как есть -- 600dpi
В строке "Metod" выберите "50% Threshold"
Можно сначала попробовать Threshold отдельно, до записи скрипта, чтобы посмотреть, что получилось. Если вам покажется лучше другой уровень Threshold, не 50%, вставьте его в Action отдельной командой, сразу после Curves.
Запускать пакетную обработку в Фотошопе, надеюсь, все умеют? Если нет, то у Фотошопа есть Help...
Следующая, 3-я, часть статьи будет посвящена работе с фильтром Smart Blur.
Может быть, я добавлю туда материалы по некоторым другим способам обработки изображений. А может быть и нет, как со временем будет.
<
Подборка статей с сайта Kpnemo.ru. Большая благодарность Ивану Сторожеву (IvanStorogev) - создателю статей, за подробные алгоритмы работы с материалом, за проделанную работу.
Обработка, компиляция в chm - Kendzin.
Как почистить сканы книг. Часть 1.
Как почистить сканы книг. Часть 2.
Как почистить сканы книг. Часть 3.
Как почистить сканы книг? Часть 3
Это окончание статьи. Тут первая и вторая части.
В третьей части я расскажу о фильтре Smart Blur и сделаю краткие выводы по всем 3-м частям статьи.
Шелкните по картинке, чтобы увеличить.
Пояснения к картинке в начале статьи (в анонсе)
Я сделал эту картинку для того, чтобы наглядно показать разницу между Smart Blur и просто Blur (Меню Filter -> Blur -> Blur more). На 3-D картинке (вверху) яркость пикселей отображена в виде трехмерного рельефа. "Щебень" у подножия горы справа -- это шум. Исходное 2-D изображение внизу. Оно ивертировано, для наглядности 3-D картинки. 3-D картинка делалась в Pov-ray.
Photoshop: Smart Blur
Вы найдете этот фильтр в меню Filter -> Blur -> Smart Blur.
Smart Blur переводится как "умное сглаживание". В научной литературе для таких фильтров обычно применяют название адаптивный -- adaptive blur, adaptive thresholding и т.п. Аналогичные фильтры есть и в других программах обработки изображения. Ищите названия со словами adaptive, denoiser и т.п. В Paint Shop Pro v9.1 схожий фильтр называется Edge Preserving Smooth (Размытие с защитой краев).
Для того, чтобы понять работу фильтра Smart Blur, немного расскажу что делает просто Blur. Blur переводится как "сглаживание" или "размазывание". Действительно, все фильтры группы Blur выравнивают значения яркости близлежащих точек, как бы размазывая изображение. При этом мелкие детали изображения могут совсем исчезнуть, а резкие переходы на границах крупных деталей делаются размытыми. То есть получается, что убивая шум (мелкие детали), обычный, "тупой", Blur попутно портит, размазывает и крупные детали, т.е. полезную, нужную нам часть изображения. Это хорошо видно на картинке в начале статьи. Похоже на утюг, который выглаживает складки изображения, но и пуговицы прихватывает.
Фильтры Blur -- просто, не Smart -- есть в Фотошопе во многих вариантах. В меню Filter имеется целое подменю Blur. Фильтр Blur относится к локальным фильтрам.
Как работают локальные фильтры? Компьютер обрабатывает всё точки изображения по очереди. Для каждой точки вычисляется. новое значение, исходя из старых значений самой точки и её ближайших соседей. Это можно представить как окошко, порядка 3x3 -- 9x9 точек, которое скользит по изображению. Для вычисления нового значения используется некая функция, определяющая какой вклад внесет в новое значение точки её старое значение и старые значения каждого из соседей. Разным фильтрам (Blur, Sharpen, High Pass)соответствуют разные функции. Именно потому, что для вычислений используют только ближайшие окрестности точки, такие фильтры и называют локальными.
Для перечисленных фильтров вид функции и коэффициенты не меняются от точки к точке, поэтому степень сглаживания не зависит от участка изображения. От того и портится вместе с шумами полезное изображение. Smart Blur меняет степень сглаживания в зависимости от характера текущей части изображения. Участки с небольшими деталями и плавными изменениями яркости фильтр размазывает сильно, а на участках с крупными деталями, большими и резкими перепадами яркостих размазывание гораздо меньше. Т.е. Smart Blur приспосабливается к изображению, потому и называется адаптивным (адаптация -- приспособление).
Пользоваться Smart Blur просто -- всего два параметра.
Radius -- радиус окошка просмотра. Threshold -- влияет на обработку краев крупных деталей изображения. Начните со значений Radius 12-16, Threshold 35-45. Эти значения можно менять в широких пределах. Не забудьте поставить Quality в High, а Mode в Normal.
Шелкните по картинке, чтобы увеличить.
Как видим, фильтр Smart Blur достаточно мощное средство очистки изображения от шумов.
После обработки фильтром Smart Blur отправляемся к Curves
Заключение
Сравнение Neat Image Pro+ и Smart Blur.
NI+ и Smart Blur используют разные подходы к удалению шума. NI+ требуется образец шума, который она "вычитает" из всего изображения, т.е. это глобальный фильтр. Smart Blur работает локально, при этом шумом считается любая мелкая (по размерам и изменению яркости) неоднородность изображения. NI+ лучше использовать когда все изображение зашумлено более-менее равномерно одинаковым шумом. Например, это может быть фактура бумаги, специфический шум именно этого экземпляра/модели сканера, фотокамеры и т.п. Smart Blur не требует никакой информации о шуме. Эти фильтры можно применять последовательно или использовать в конкретном случае только один из них. Если вы будете применять оба фильтра помните: сначало нужно обработать картинку NI+, а потом Smart Blur. Не наоборот! Почему именно так, надеюсь, очевидно. Верно? ;-)
Имейте ввиду, NI+ это вообще-то целая программа, а не отдельный фильтр. На самом деле в ней используется более сложная обработка, чем я тут написал, в частности можно усиливать края деталей изображения, управлять размытием и т.д.
Кроме Neat Image Pro+ есть и другие программы/плагины к фотошопу со схожими возможностями. Особенно рекомендую Noise Ninja, о ней упоминали в комментах к первой части статьи, и Noiseware Professional Plug-in for PS. Не обязательно работать в Фотошопе. У других растровых графических редакторах, например Paint Shop Pro v9.1, возможности, в части чистки сканов, не хуже.